Software
|
lunes, junio 1, 2015
|
|
Esta semana pasada en el evento anual Google IO 2015, la empresa anunció (como esperado cada año) la nueva versión de Android, a la que llamó por ahora "Android M" (y muchos llamarán Android 6.0 hasta que Google le de un nombre oficial), así como hizo unos cuantos otros anuncios relacionados, y he aquí lo que más me llamó la atención más otras observaciones...
 1. Android M, es la evolución de Android 5, esta vez pensando no tanto en cambiar mucho el look visual del sistema operativo, sino en proveer muchas funcionalidades ya existentes en la competencia, así como un par nuevas que sin duda serán de mucha utilidad. 1. Android M, es la evolución de Android 5, esta vez pensando no tanto en cambiar mucho el look visual del sistema operativo, sino en proveer muchas funcionalidades ya existentes en la competencia, así como un par nuevas que sin duda serán de mucha utilidad.2. Android M ahora vendrá con soporte nativo para leer huellas digitales, trayendo paridad a Android con la tecnología de TouchID de Apple. Aunque ojo, Google solo provee la especificación, y será ya labor de los fabricantes el implementar a su gusto. Esto significa que la experiencia va a variar dependiendo del proveedor. 3. Google reveló por fin cómo funcionará Android Pay, que es la evolución del fracasado Google Wallet, esta vez imitando el modelo más práctico de Apple Pay, incluyendo la capacidad de pagar con tu huella digital al estilo iPhone 6. 4. Si nos llevamos de esos dos últimos puntos, podríamos adivinar que los próximos celulares Nexus de Google vendrán con soporte integrado de lectores de huellas digitales (especulación educada de mi parte). 5. Google anunció Google Photos, en esencia desprendiendo la funcionalidad de fotos de Google+, pero permitiendo algo extremadamente útil para usuarios: Totalmente gratis Google permitirá que almacenes una cantidad totalmente ilimitada de tus fotos y videos en Google Photos. Sí, gratis. Sin embargo, existe una limitante que es bueno notar: Los videos no pueden pasar en resolución de 1080p (como por ejemplo, video UHD o 4K), y las fotos no pueden pasar de 16 Megapixeles. En ambos casos Google no rechaza los videos ni las fotos que sobrepasen esos límites, sino que simplemente les reduce la resolución a 1080p y 16MP respectivamente (cosa que es bueno notar para profesionales que quizás no deseen esto). Noten que Amazon Prime, aunque un servicio pagado (pero que ofrece muchísimas ventajas, desde envíos gratis y acceso a una gran librería de películas y canciones) permite también subir una cantidad ilimitada de fotos y videos, en cualquier resolución y formato (incluso RAW) a Amazon Prime Photos, por lo que si son profesionales quizás quieran investigar esa opción. Google Photos para Android Google Photos para iOS 6. Android M ahora permitirá también poder controlar los permisos de las aplicaciones a un nivel mucho más granular, y solo cuando son necesitados. Eso significa que ahora en vez de los usuarios tener que otorgar permisos a las aplicaciones a la hora de instalar, que lo pueden hacer en el momento de correr la aplicación y solo cuando sea necesario. Un ejemplo de esto es una aplicación que después que arranque te pida permiso para utilizar tu micrófono, o la cámara. Noten que esto es imitando el comportamiento de iOS en ese aspecto, y que sin duda será aplaudido por desarrolladores de software ya que hace más probable que los usuarios utilicen sus aplicaciones. 7. Android M también vendrá con la capacidad de formatear una tarjeta MicroSD (para aquellos equipos que lo soporten) de modo que funcionen como memoria expandida del sistema. Esto será de gran ayuda para los millones de dispositivos Android que vienen con con 2 o incluso 1GB de memoria interna, pero ojo que esto podría hacer un poco más lento el rendimiento de tales aplicaciones, aunque al menos permitirá que se ejecuten... 8. Android M también vendrá con soporte nativo para USB-OTG, lo que permitirá que uno conecte discos externos a celulares Android por medio de adaptadores USB, para utilizarlos como almacenamiento externo de gran capacidad. Noten que algunos dispositivos Android (como las tabletas Nexus ya tenían soporte para USB-OTG desde hace tiempo, pero ahora esto estará disponible para todo dispositivo que soporte Android M.  9. Google también anunció Expeditions, una herramienta de Realidad Virtual que utiliza el accesorio Google Cardboard VR (en esencia, un kit de cartón con par de lentes, a un precio menor a los US$30 dólares, y que conectas a tu celular para crear una versión ultra-barata de unas gafas de realidad virtual), para permitir que profesores y estudiantes visiten "en grupo" (es decir, de forma simultánea) muchos lugares de interés educacional y cultural del mundo, pero en Realidad Virtual. Google también anunció que su Google Cardboard VR ahora también estará disponible para iPhone.  10. Finalmente, Google anuncio Google Jump VR, un hardware que consiste de 16 cámaras GoPro, más software especializado desarrollado conjuntamente entre Google y GoPro, que une la vista de esas 16 cámaras (colocadas en un círculo) para crear video de 360 grados que pueden posteriormente ser visto en YouTube, o mejor aun, con accesorios de Realidad Virtual como el Cardboard VR. Y eso es en resumidas cuentas lo que me encontré más interesante de Google IO 2015. Si tienes sus otros favoritos, no duden en darlos a conocer en los comentarios abajo. Actualización 1: Como bien me alertó la lectora Cecilia Abadie en los comentarios, otro de las grandes cosas anunciadas por Google en este evento fueron sus mejoras para Google Now (a lo que llamó "Google Now on Tap"), que ahora más que nunca se adelanta a tus necesidades para sugerirte cosas en tu agenda, notificaciones, etc. Noten que los rumores esperan que Apple imite esta funcionalidad en iOS 9 con algo que supuestamente llamará "Proactive". Actualización 2: Me acabo de enterar que Google Photos tiene un buen truco bajo la manga: Búsquedas contextuales. Eso significa por ejemplo que puedes buscar por contenido visual de las imágenes, como por ejemplo buscar por fotos que contengan un automóvil, o la torre de París, etc. Y de forma similar, si tu cámara o celular no le provee a las fotos de geo-localización (es decir, en dónde fue tomada la foto, para ser desplegado posteriormente en un mapa), Google te da la opción de identificar el lugar basado en su contenido (por ejemplo, una foto con la Estatua de la Libertad de fondo probablemente fue tomada en New York). Actualización 3: Como bien indica el lector Esteban Alvarez en los comentarios, Google Maps ahora se podrá utilizar en modo offline (sin internet), y eso incluye incluso el buscar y obtener direcciones para llegar al destino. Actualización 4: Otro adelanto interesante es que Android M también soportará nativamente el nuevo estándar USB Type-C, el mismo que Apple implementó en su nueva MacBook. Este tipo de conectores no solo es super rápido (unos 5Gbps), sino además que puede proveer tanto de datos como de energía al dispositivo por un solo cable. Actualización 5: Android M también soportará el estándar protocolo de música MIDI, algo que por años ha proveído una ventaja a iOS en el mundo de la música digital. autor: josé elías |
|
|
|
|
|
viernes, marzo 27, 2015
|
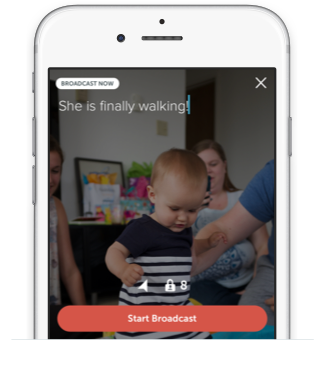 Y ahora Twitter lanza otra aplicación que se va al otro extremo, no permitiendo mensajes de 140 caracteres, sino video en tiempo real de largo ilimitado... El servicio se llama Periscope, y lo que hace lo hace bien y sobre todo extremadamente simple: Simplemente instalas el App en tu iPhone (la versión de Android llegará en las próximas semanas (actualización: Ya está disponible desde el 26 de Mayo 2015)), inicias el video, y todo lo que estés viendo tu en ese momento a través de tu celular lo verán en ese mismo instante (es decir, en tiempo real), todas las personas que se hayan subscrito a ver tus videos. E incluso, los que no empezaron a ver inmediatamente tu video en vivo no se perderán de nada, ya que los videos son almacenados por 24 horas para el disfrute de los que llegaron tarde a la transmisión. Noten que el concepto de video en vivo no es nuevo per-se, pues incluso Google permite generar "Hangouts" en tiempo real para el consumo de quien desee verlos, pero soluciones como las de Google y otros son añadidos a otros servicios (en el caso de Google, a YouTube), y no son ni remotamente tan fáciles de utilizar como es Periscope. Yo personalmente me he tenido que resistir a transmitir cosas en vivo en YouTube precisamente por la complejidad del proceso (y les habla un usuario bastante técnico que no tendría problemas en averiguar los pasos necesarios para utilizar el servicio). Pero con Periscope los pasos son los siguientes: 1. Lanzas la aplicación. 2. Haces clic sobre el botón de empezar a transmitir. Y eso es todo, en serio, no hay otros pasos (salvo la primerísima vez que lances el programa, en donde el celular te preguntará si le das permiso a Periscope a utilizar tu cámara, micrófono, y opcionalmente tu localización). Después desde que inicias a mostrar video, todos tus seguidores obtienen una notificación (el sistema está integrado con Twitter mismo), y pueden empezar a sintonizar con el App. Noten que ya existe otra App similar llamada Meerkat, pero creo que Periscope con el empuje de Twitter y su super simpleza será la que termine dominando este mercado nicho, aun haya llegado de segundo. Y para los curiosos, sepan que Periscope no fue originalmente desarrollada por Twitter, sino por otra empresa recientemente, y Twitter los compró inmediatamente por unos US$100 Millones de dólares... En mi opinión, esta aplicación podría revolucionar la forma en que vemos el mundo, por fin permitiendo una comunicación con video en tiempo real que nos muestre lo que pasa en el planeta en este preciso instante. Puede ser que veamos desde el nacimiento del bebé de unos amigos o familiares, o un desconocido reportando sobre un incidente de transcendencia, o quizás alguien dictando una conferencia, o posiblemente un profesor enseñando a miles de estudiantes a la vez, y no dudemos del potencial que sin duda le verán los mercadólogos a esta plataforma (y no olvidemos la industria de la pornografía que sin duda verá en esto otra forma de hacer dinero). Y ojo, que aunque no sea Periscopio quien termine dominando este mercado, que pueden estar seguros que este concepto está para quedarse y que será parte de nuestras vidas sociales virtuales de ahora en adelante de forma permanente. Yo personalmente acabo de probar la aplicación y es asombrosa lo simple que es, y estoy seriamente pensando en utilizarla para transmitir algunas cosas en vivo que se me ocurren, así que si quisieran ser notificados, descarguen la aplicación ya y agréguenme para seguirme por "eliax" (apareceré como "José Elías - eliax"). Para agregarme entren al App, hagan clic en el icono de abajo a la derecha (el ícono de las tres personas), y después hagan clic en la lupa al tope izquierdo para buscar, y ahí entren "eliax" y saldré inmediatamente. Otra cosa interesante de Periscope es que mientras ven un video pueden interactuar con quien lo emite, sea con mensajes o tocando la pantalla una o varias veces repetidas, que tiene como resultado enviarle "corazoncitos" al que emite el video, como señal de que te gusta lo que ves (en esencia, estos corazones son el equivalente de los "Like" o "Me gusta" de Facebook y otras redes sociales como Instagram). Finalmente, ahora solo quiero dos cosas de esta App: (1) que salga la versión Android, y (2) que agreguen alguna funcionalidad para uno poder programar eventos con antelación para que las audiencias sepan cuando esperarlos. Y sería genial si YouTube y Facebook crearan aplicaciones similares y así de sencillas para acelerar este tipo de herramientas en el mercado... página oficial de Periscope Enlace para descargar en el App Store para el iPhone Actualización 26 de Mayo 2015: La versión de Android ya está disponible para descargar aquí. autor: josé elías |
|
|
|
|
|
lunes, enero 19, 2015
|
|
Hoy los dejo con un video de una increíble tecnología desarrollada en Carnegie Mellon University en los EEUU en donde es posible tomar una fotografía normal en 2D, elegir un objeto tridimensional de esta, y manipularlo al antojo en su entorno fotográfico.
Esta es una de esas cosas que hay que ver para entender (y creer). De la manera que esta tecnología funciona es consultando primero una base de datos de objetos tridimensionales (de los cuales ya posee información de la forma volumétrica del objeto), y después utilizar esa información para reconocer objetos similares en la fotografía. Cuando reconoce el objeto, el software reemplaza el objeto de la foto por el objeto 3D, pero manteniendo las propiedades de color, textura y sombras del original, para aparentar que uno lo está manipulando directamente. Noten que esto está relacionado a otra tecnología que inserta objetos virtuales 3D en fotografías 2D, y de la cual les hablé acá mismo en eliax hace unos años. Y también está relacionado a esta otra tecnología que extrae imágenes 3D de fotografías 2D. página oficial del proyecto Y si quieren hacer que esta herramienta se haga realidad para el público en general, contribuyan con la campaña crowdsource en este enlace. ¡Gracias al lector Erik Roy por compartir el video en el grupo oficial de #eliax en Facebook! Video a continuación (enlace YouTube)... Video expandido a continuación, con más detalles (enlace YouTube)... autor: josé elías |
|
|
|
|
|
jueves, enero 15, 2015
|
 Si alguna vez haz tenido la necesidad de controlar tu PC/Laptop remotamente, es posible que seas un usuario semi-técnico que haya utilizado herramientas como TeamViewer, Splash Desktop, Microsoft RDP, o Log Me In, ¿pero sabías que Google ofrece una herramienta para hace justo eso, totalmente gratuita, y que ahora también funciona desde dispositivos móviles como Android, iPhone y iPad? Si alguna vez haz tenido la necesidad de controlar tu PC/Laptop remotamente, es posible que seas un usuario semi-técnico que haya utilizado herramientas como TeamViewer, Splash Desktop, Microsoft RDP, o Log Me In, ¿pero sabías que Google ofrece una herramienta para hace justo eso, totalmente gratuita, y que ahora también funciona desde dispositivos móviles como Android, iPhone y iPad?La herramienta se llama Chrome Remote Desktop y permite hacer justo eso: Desde otra PC o móvil puedes controlar una PC (ambas obviamente deben estar ejecutando la aplicación Chrome Remote Desktop), lo que está genial o para hacer algo rápido en tu propia PC, o para ayudar a alguien más con algún problema que tenga. Es importante notar que para que esto funcione la persona propietaria (o que controla localmente) la PC remota debe ofrecerte permiso explícito para que accedas a su máquina, y esto se hace con un código que se general localmente y que debes de alguna manera hacer saber a la persona remota para que se conecte a tu PC (de forma muy similar a como funciona TeamViewer). Es importante notar que Chrome Remote Desktop funciona en dos modalidades diferentes, funcionando como una sesión temporal para asistencia remota (sea que te asistan a ti, o que tu quieras asistir a alguien más), o como una sesión permanente en donde puedes acceder a tu PC en cualquier momento con un mismo código (en cuyo caso, debes dejar tu PC encendida cuando salgas de casa u oficina para que esta tenga conexión a Internet cuando te quieras conectar a ella). Noten además que como se imaginarán, la aplicación requiere de una instalación y configuración de una sola vez, la cual inicia, apropiadamente, desde el navegador Google Chrome, visitando la dirección chrome.google.com/remotedesktop (desde otros navegadores no podrán instalar nada). Algo genial es que Chrome Remote Desktop funciona no solo en Windows, sino además en Mac OS X y Linux. En mi experiencia, la velocidad de actualización de la imagen remota es bastante fluida si tienes una conexión de Internet estable, particularmente dado el hecho que Google utiliza su super-eficiente CODEC de video VP9 para refrescar la pantalla, y convenientemente hasta el sonido de la pantalla remota lo puedes escuchar localmente. Noten sin embargo que usuarios más técnicos quizás deseen permanecer con soluciones más especializadas que esta, ya que Chrome Remote Desktop no ofrece capacidad para por ejemplo transferir archivos, ni tampoco es muy amigable a ambientes remotos que contengan más de un monitor (puedes ver varios monitores, pero de forma disminuida y simultánea, o teniendo que deslizarte constantemente, sin capacidad de fácilmente poder cambiar entre un monitor y otro directamente). Pero aun así, para soporte técnico casual, y para uno incluso trabajar esporádicamente en nuestros equipos remotos (o incluso para ofrecer alguna presentación remota), Chrome Remote Desktop está más que genial, y siendo un servicio gratuito no nos podemos quejar mucho... Página oficial de Chrome Remote Desktop (debes acceder a este enlace con el navegador Google Chrome para instalar la extensión de Chrome, el cual después te dirigirá a una instalación local nativa para tu PC). En Android, iPhone o iPad busquen por "Chrome Remote Desktop" en sus respectivas tiendas de aplicaciones para encontrar la app nativa móvil. autor: josé elías |
|
|
|
|
|
viernes, octubre 3, 2014
|
|
Hoy los dejo con este video que fue subido a Internet de mi más reciente charla (de esta misma semana) en el 24 Encuentro GeneXus (GX24) en Montevideo, Uruguay, uno de los eventos de tecnología más importantes (y grandes) de América Latina, en donde miles de desarrolladores se reúnen cada año para compartir experiencias, aprender y ver las últimas novedades de la plataforma GeneXus (de la cual les hablé acá mismo hace unos años atrás). Esta fue mi quinta intervención anual en tal evento, y como siempre la pasé genial. El título de esta charla fue "Recetas del éxito (y fracaso) de los titanes [de la industria]". Una observación que les tengo (y que se les hará obvia al ver el video) es que mi tiempo era muy limitado. Mi charla realmente debería durar oficialmente solo 30 minutos, pero me concedieron 45 (ya que como siempre, me ponen a hablar de último en el día), aunque realmente necesitaba 60 minutos, por lo que excusen la rápida dicción de mi parte ;) Video a continuación (enlace YouTube)... autor: josé elías |
|
|
|
|
|
lunes, agosto 11, 2014
|
|
¿A qué me refiero con secuencial en vez de no ser aleatoria? A que increíblemente los humanos (y posiblemente el resto del reino animal) no podemos recordar cosas al azar, sino que siempre tenemos que seguir una secuencia, ya que nuestras memorias están almacenadas una al lado de la otra, como si fuera una cinta de audio de los 1980s... Eso para algunos sonará un tanto falso, ya que aparenta que podemos recordar cualquier cosa que nos de la gana en cualquier orden, pero eso es una ilusión, ya que para recordar cualquier cosa siempre tenemos que tener un punto de partida, un punto de referencia, y es después de ese punto de partida que recordamos lo que sigue. Y creo que no hay mejor manera de demostrarlo que en un ejemplo que leí recientemente (y con el que estoy seguro algunos de ustedes han intentado al menos una vez en sus vidas): Recitar el alfabeto de atrás hacia adelante, empezando con la letra "Z" y terminando con la letra "A". Inténtelo ahora mismo a ver qué tan rápido pueden hacerlo. Y no solo eso, tomen nota de cómo lo hacen... Es posible que se hayan dado cuenta que es un trabajo muy difícil, y lento, ya que la única manera que podemos saber que antes de la "Z" viene la "Y", y que antes de la "Y" viene la "X", es enlazando a estas en el orden que ya es familiar para nosotros, de adelante hacia atrás (es decir, de A a Z). Y si no les es obvio, traten el ejemplo no solo con las últimas letras del abecedario, sino que literalmente traten de llegar hasta la misma "A" desde la "Z". ¿Qué les dice esto? Pues para empezar que la única razón por la cual recuerdan el orden del abecedario es porque tienen en sus cerebros almacenados el orden explícito de una letra conectada a la otra, en una secuencia, y que la razón por la cual se hace tan difícil recitar el alfabeto al revés es porque sencillamente no tenemos memoria almacenada de la secuencia alterna de la Z a la A ya que eso rara vez lo practicamos. Obviamente con práctica podemos aprender a memorizar el orden inverso, y eso nos lleva a otro punto: El aprendizaje inicial de cualquier cosa es traumático y lento, ya que nuestros cerebros son lentos (aunque no lo crean, en lo que le toma a una neurona responder a un estímulo en 5 milisegundos (5ms), un transistor en cualquier celular puede responder miles de millones de veces). Esa es la razón por la cual los niños no aprenden el abecedario en un solo día, pues le cuesta al cerebro acostumbrarse a asociar la secuencia de las letras. Y es la misma razón por la cual si aprendes a jugar Ping Pong, no serás un maestro el primer día, ya que tu cerebro tiene que crear una secuencia de movimientos (memoria muscular) hasta que aprendas bien cómo reaccionar ante la pelotita. Así que si son programadores de software, una forma de ver esto es que nuestras mentes almacenan memoria al estilo de un linked list (lista encadenada), en donde un objeto apunta al siguiente, y no al estilo de una memoria RAM con acceso aleatorio. Otro ejemplo más complejo que se me ocurre es recordar cómo llegar a algún lugar para un viaje de verano. Es imposible visualizar por lo general todo el recorrido simultáneamente en tu mente, pero sin embargo de alguna manera llegas a tu destino, pues sales de tu casa, y sabes que el primer paso es llegar a tal calle, después a tal autopista, después a tal pueblo, y después doblar en tal esquina, y después llegar a tal casa en la playa o la montaña. Es decir, una serie de pasos. Pero esto tiene otra gran curiosidad que tiene que ver con cómo el cerebro ha evoluciona para aparentar ser tan rápido en relación a una máquina moderna... Noten por ejemplo que aunque el cerebro es un órgano altamente paralelizable (es decir, que ejecuta muchas instrucciones en paralelo), que el hecho que le tome hasta 5 ms a una neurona responder significa que por más computación que haga el cerebro en paralelo, que este sencillamente no puede romper las reglas de la física y obtener respuestas más rápidas que esos 5ms. Pero entonces, ¿cómo puede el cerebro hacer cosas como reconocer patrones tan rápidamente, y aparentar ser mucho más rápido que cualquier super computadora? Pues el cerebro hace trampa con un truco muy conocido a los programadores de software (que revelaré en un instante)... Y para entender de lo que hablo, imaginen el siguiente ejemplo: Tenemos una habitación totalmente blanca, en forma de cubo, sin nada en las paredes ni pisos. En un extremo sentamos a una persona y a su lado a una computadora con una cámara, y ambos miran hacia el otro extremo de la habitación, y ahora vamos a poner a estos dos seres a competir... La competencia será la siguiente: Al otro extremo de la pared pondremos varios objetos (uno a la vez), desde animales hasta sillas y frutas, y el trabajo del ser humano y la máquina es reconocer qué es lo que les presentan frente a ellos lo más rápidamente posible. Así que digamos que les presentamos a ambos un gato, y veamos cómo reconocen cada uno de estos dos participantes al gato... La computadora inicia ejecutando un potente algoritmo computacional que aísla al gato de su entorno blanco. Después ejecuta otros cálculos para reconocer su contorno. Después ejecuta más cálculos para empezar a hacer segmento por segmento de la imagen resultante comparaciones con una potente base de datos de gatos que posee, comparando pixel por pixel, haciendo todo tipo de cálculos y transformaciones matemáticas, hasta por fin dar con una imagen que se parece a la de un gato. En esencia, la computadora computa. Calcula. Y hace miles de millones de cálculos para poder llegar por fin a la conclusión de que frente a ella hay un gato. Vamos ahora al humano (y ver como hace "trampa", aunque en realidad es una optimización evolutiva, como veremos)... Al ojo del humano llega la imagen del gato, la cual es transformada casi instantáneamente a impulsos eléctricos en el ojo que viajan hasta los reconocedores de patrones del cerebro. Cuando estos impulsos llegan al reconocedor de patrones, ocurre algo muy interesante: El patrón generado por esos impulsos eléctricos actúa como una llave o código que apunta de forma difusa a los bancos de memoria que contienen todo tipo de recuerdos (en este caso, visuales). Es decir, el patrón eléctrico que llega a las neuronas funciona como un nombre en una guía telefónica, en donde el nombre es la llave, y el resultado es el número telefónico de quien estás buscando. O en otras palabras, la imagen misma que viaja desde el ojo codificada como impulsos eléctricos, es la clave para que el cerebro busque en su cerebro una imagen de un gato previamente almacenada. Y ahí es en donde yace el truco: El cerebro humano en la mayoría de casos, no tiene que hacer ningún cálculo complejo, sino que lo que hace es que simplemente busca recuerdos similares en donde el cálculo ya se ha realizado previamente. O en otras palabras, la primera vez que de niño ves un gato, tu cerebro tiene que hacer tantos cálculos como lo hace una computadora para entender lo que ve, pero después de eso el cerebro almacena un patrón en forma de gato (o más bien, con el mismo patrón que surge eléctricamente cuando la imagen de un gato entra por tus ojos) que activa la imagen misma del gato almacenada. Eso significa que la razón por la cual el humano de este ejemplo hipotético es tan rápido como la supercomputadora es porque el humano no tiene que hacer esos cálculos en el momento del concurso, sino que ya ha realizado esos cálculos previamente y ahora es solo cuestión de llamar la memoria perteneciente al gato. Para los que son programadores de software, esto es lo mismo que crear un lookup table (una tabla de búsqueda), en donde el key (llave) es el patrón de los impulsos eléctricos que entran visualmente por el ojo, y el value (valor) es la imagen previamente (y correspondiente) al key. En un video-juego por ejemplo, hay dos maneras de calcular los ángulos de los objetos geométricos que vemos en pantalla: Una es calcular los ángulos resolviendo ecuaciones complejas, pero otra mucho más eficiente (y que es la práctica estándar en el arte de los video-juegos) es pre-calcular todos los ángulos posibles para tener las respuestas ya listas, de modo que si surge la pregunta "¿Cuál es el ángulo de ataque del enemigo en relación a la pared de 30 grados?" que uno no tenga que empezar a resolver ecuaciones de ángulos complejas, y en vez de eso simplemente va a nuestra lookup table y pregunta "La última vez que calculé el ángulo de ataque para una pared de 30 grados, ¿cuál fue el resultado?", lo que es una operación posiblemente miles de veces más rápida que tener que hacer el cálculo otra vez. Y todo esto nos devuelve al tema de la memoria secuencial... Estos patrones de gatos y otros objetos que almacenamos en el cerebro, son reconocidos y almacenados de forma lineal, uno al lado del otro. De modo que por ejemplo si en un futuro vemos un nuevo tipo de gato, muy similar al que teníamos almacenado pero de otro color, nosotros lo asociamos secuencialmente al primer gato, y ya tenemos una idea que es un gato, pero con alguna diferencia. Es como almacenar en el abecedario la letra "P" y después entender que la letra siguiente es la "Q". Finalmente, es bueno entender que unas personas dependen más de la secuencialidad que otras, y por eso se da el caso de personas que sencillamente nunca pueden llegar a un punto en ninguna conversación (o al menos no pueden llegar al punto rápidamente), ya que sus mentes funcionan demasiado secuencial, y no pueden ver más allá de unos pocos pasos hacia el futuro para poder resumir sus pensamientos brevemente. ¿Curioso, no? autor: josé elías |
|
|
|
|
|
domingo, julio 13, 2014
|
 Si me preguntan, ¿cuál es el navegador web más avanzado del mundo jamás creado? Mi respuesta no sería ni Google Chrome, ni el Safari de Apple, ni Mozilla Firefox, ni Microsoft Internet Explorer, ni el navegador Opera... Si me preguntan, ¿cuál es el navegador web más avanzado del mundo jamás creado? Mi respuesta no sería ni Google Chrome, ni el Safari de Apple, ni Mozilla Firefox, ni Microsoft Internet Explorer, ni el navegador Opera...Sería un navegador del cual estoy seguro la mayoría de los lectores de eliax nunca han escuchado, y que salió públicamente en 1995 gracias a unos hackers de Sun Microsystems (los mismos creadores de Java, y hoy día propiedad de Oracle). Ese navegador se llamó HotJava, y fue un proyecto ambicioso pero lamentablemente muy adelantado a su tiempo... HotJava fue un navegador web escrito enteramente en el lenguaje de programación Java, y que tenía la particularidad de que era totalmente dinámico y extensible en Java mismo. Eso significa que cualquier desarrollador podía ofrecer módulos en Internet que al ser instalados por los usuarios con un par de clics, modificaban y extendían el mismo núcleo del navegador en formas inimaginables. Y ojo, que no hablo de simples extensiones como es común hoy día en cualquier navegador, sino el poder cambiar el navegador mismo para que este evolucione dinámicamente con nuevas tecnologías. Hablamos de por ejemplo el poder soportar nuevos estándares de video dinámicamente sin necesidad de tener que esperar a que los que desarrollaron el navegador mismo agregaran tal funcionalidad. Pero aun siendo una de las obras de ingeniería de software más asombrosas de todos los tiempos, HotJava fue un fracaso... ¿Por qué fracasó? Pues lamentablemente aunque la arquitectura de software del navegador en sí estaba adelantada a su tiempo, el hardware ni los otros elementos necesarios para hacer a HotJava lo suficientemente rápido, estaban disponibles hace 19 años atrás. HotJava era relativamente lento en comparación a otros navegadores de la época, y además Sun Microsystems, no tenía experiencia mercadeando sus productos fuera del sector empresarial. HotJava necesitaba en esos tiempos no solo hardware más potente, sino además un runtime basado en máquinas virtuales (en donde ejecutaba Java) que fuera más potente, como lo es la JVM (Máquina Virtual de Java) de hoy día, que no solo interpreta código sino que incluso lo compila a formato nativo para aumentar considerablemente su rendimiento a niveles casi de código nativo. Pero avancemos ahora 19 años al día de hoy, y ha surgido una nueva opción que podría hacer el sueño de HotJava realidad: Breach. Breach es un navegador que un grupo de talentosos hackers inició a finales del año pasado, y que por fin revelan públicamente ahora, y que tiene la particularidad de ser construido sobre una plataforma dinámica de Javascript. Javascript es un lenguaje originalmente pensado para simples tares interactivas en páginas web, pero cuya importancia ha crecido considerablemente en años recientes, gracias principalmente a la rivalidad entre los distintos fabricantes de navegadores web que desean siempre poder mostrar las páginas web más rápidas en sus renderizadores, que en los navegadores de sus competidores. Eso ha llevado a que se hayan creado unos runtimes para Javascript extremadamente optimizados, en donde el código ejecuta ya a velocidades no muy distantes de aplicaciones nativas, y en algunos casos incluso mucho más rápido que aplicaciones nativas en hardware de apenas 5 años atrás. El crecimiento de Javascript ha sido tal, que lo considero incluso el nuevo lenguaje más importante a aprender en entornos no solo de clientes (en navegadores) sino de servidores, gracias a herramientas como Node.js. Breach entonces toma ventaja de todo este nuevo ecosistema de Javascript, mezclando justamente muchos de los elementos de Node.js, con el motor de Javascript open source desarrollado por Google para Chrome llamado V8, para con un poco de código adicional crear toda una nueva plataforma para lo que sería el primer navegador web realmente dinámicamente extensible desde HotJava hace casi dos décadas atrás. Breach quizás no se convierta en el navegador web que finalmente acabe con el reinado de Google Chrome (que debo agregar por años ya ha sido mi navegador web favorito), pero de no hacerlo es posible que inspire a quien finalmente lo haga, sino es que alguien como Google mismo lo adopte (o imite) como la arquitectura para sus futuros navegadores... En Breach, todo es un módulo escrito con Javascript y renderizado con HTML5 (si tiene un componente visual), y toda su estructura puede cambiarse dinámicamente y de forma segura (a diferencia de node-webkit, que realmente fue diseñado para aplicaciones locales y por tanto no tiene un requerimiento de seguridad muy fuerte), permitiendo por ejemplo que los usuarios modifiquen por completo la funcionalidad y la forma en que se ve su navegador. Esta personalización obviamente no será para todo el mundo, ya que la mayoría quizás prefiera un ambiente sencillo y funcional sin muchas complicaciones (por eso existen por ejemplo las opciones de Android y iOS en el mundo, o de Windows vs Linux), pero sí servirá cuando menos para dejar las bases de una nueva generación de software que literalmente evoluciona por sí solo, de forma dinámica, sin la necesidad de un control centralizado. O en otras palabras, de una forma similar a como funciona la evolución en todas sus formas en la naturaleza. Si están curiosos de probar a Breach, visiten el website oficial y descarguen el software. Lo he probado en mi entorno Mac y he quedado totalmente sorprendido. Aun siendo software en etapa "Alpha" (es decir, ni siquiera "Beta" para pruebas), me ha sorprendido su velocidad. Las páginas inicialmente cargan más lentas que en otros navegadores, pero desde que ocurre esa primera descarga el navegador y su motor V8 optimizan su código interno, y subsiguientes descargas ocurren casi inmediatamente, con posterior velocidad casi indistinguible de cualquier otro navegador en la mayoría de los casos. Así mismo noten que software al estilo Alpha no es para todo el mundo, y que es bueno saber lo que hacen (y lean lo que les pone Breach en pantalla la primera vez que lo lanzan, o no entenderán cómo utilizarlo), pero como un vistazo al futuro, lo considero invaluable. El próximo paso para los creadores de Breach es congelar la funcionalidad básica para exponer un API (interfaz de programación) ya estandarizada al cual cualquier desarrollador pueda tener acceso, algo que posiblemente veremos en la primera versión Beta en los próximos meses. página oficial de Breach información técnica de Breach autor: josé elías |
|
|
|
|
|
jueves, junio 26, 2014
|
|
Leer el resto de este artículo... autor: josé elías |
|
|
|
|
|
martes, junio 10, 2014
|
 Se trata de servicios de localización móvil, o mecanismos que permitirán saber a quienes fabrican nuestros celulares, y a quienes nos proveen de servicios y aplicaciones a través de estos, nuestro lugar exacto en el mundo. Y no, no estoy hablando de la tecnología satelital GPS que hemos tenido desde los primeros iPhones (y mucho antes que eso en otros dispositivos especializados), sino de localización particularmente en interiores (aunque nada evita que se utilice en exteriores, como en conciertos), o en zonas geográficas bien limitadas y restringidas, como dentro de un shopping mall (centro de compras), restaurantes, cines, bancos, supermercados, etc... La empresa que lanzó la primera gran piedra en este mercado fue Apple, quien el año pasado lanzó su tecnología iBeacon (y del cual escribí todo un editorial que complementa bastante bien a este), una tecnología que permite que tu iPhone (o iPad o iPod Touch) sepan con tremenda exactitud donde dentro de un espacio especificado estás, como por ejemplo, sentado en una mesa en específico en un restaurante, o en una sala de espera de un banco, o quizás frente a una escultura en particular en algún museo. Asombrosamente, Apple tenía años planeando esto, y es parte de la razón por la cual ya incluso el iPhone 4S de hace unos años atrás viene con el hardware interno necesario para soportar los iBeacons, y ahora que Apple tiene cientos de millones de dispositivos capaces de detectar estas zonas virtuales, la empresa ha iniciado su asalto para su comercialización y adopción. En EEUU por ejemplo ya las ligas profesionales de Baseball y Basketball han anunciado el apoyo a esta tecnología, para ofrecer una experiencia única y personalizada a cada visitante de sus estadios, y ya se han iniciado pruebas en importantes cadenas comerciales que van desde ropa hasta comida en los EEUU, todo esto en preparación a lo que desde hace 4 años vengo vaticinando: Un sistema de pagos por parte de Apple atado a iTunes (leer por ejemplo este editorial reciente del año pasado). Y ahora, tenemos noticia (como les informé hace poco con la fuente en el grupo Developers X en Facebook) en forma de rumores bastante confiables de que Google (tal cual todos esperábamos) entrará también en este mercado para competir contra la plataforma iBeacon de Apple. Google, al igual que Apple, se ha estado armando hasta los dientes para esta batalla, muestra de eso siendo su adquisición el año pasado de Bump (la aplicación que permite que choques físicamente dos celulares para iniciar una transferencia de un archivo entre ambos por ejemplo), y de SlickLogin (que permite autenticar en formas no-convencionales, como por ejemplo via señales de WiFi, ondas de sonido, o señales de Bluetooth). Según los rumores, la plataforma de Google se bautizará con el nombre de "Nearby" ("Cercanía"), y como es natural, hará su debut próximamente en una nueva versión de Android (o quizás como una extensión a versiones existentes de Android, que sería lo ideal, dado el grado de fragmentación y baja adopción de nuevas versiones de Android en el mercado). En cuanto a la filosofía de ambos servicios, Apple ha optado por una que ofrece control a los usuarios finales (estos pueden permanecer totalmente invisibles, y sus datos no son reportados a Apple) y flexibilidad a los comercios (que simplemente colocan sus "beacons" (o "faros") y esperan a los clientes), mientras que Google ha optado irónicamente por una filosofía de control, en donde toda la infraestructura pasa por los servicios de nube de Google, siendo obligatorio incluso que para que los usuarios activen a Nearby que estos se sometan obligatoriamente a tener sus localizaciones monitoreadas por Google (y subsecuentemente disponible en Google Maps como trazos de todos los lugares en donde has estado). En el caso de Apple, esta se puede dar el lujo de hacer esto ya que la inteligencia de los iBeacons reside localmente en sus dispositivos con iOS, y en las aplicaciones que terceros elaborarán, pero en el caso de Google esta es una empresa que vive de la publicidad y debe mantener un control que le permita gestionar sus anuncios de forma personalizada, siendo tu localización geográfica uno de los puntos claves para esta generar publicidad más efectiva. Así mismo, la inteligencia en el lado de Google yace en su nube, en donde esta deduce tu localización en base a los innumerables datos que posee sobre ti, incluyendo no solo tu localización GPS, sino incluso las páginas que visitas, y con esta tecnología, los lugares que frecuentas. Y en todo este panorama, no podemos olvidar titanes como Facebook y Amazon, quienes también de una forma u otra entrarán a este mundo, sea por medio de los celulares mismos de la competencia, o con una nueva generación de dispositivos (como los rumoreados celulares de Amazon que serán anunciados muy posiblemente el próximo día 18 de Junio, como les informé vía Twitter hace poco). Si lo ponderan un poco, este tipo de tecnología será una potente mezcla a nuestras redes sociales, pues ahora empresas como Facebook podrán personalizar aun más nuestra interacción con otras personas cercanas físicamente a nosotros, así como bombardearnos con anuncios locales (¿qué tal el especial de hamburguesa que aparecerá en tu muro de Facebook justo para el restaurante en donde estás entrando ahora mismo?). Y todo esto es apenas el comienzo. No duden que veremos una manada imparable en los próximos meses/años de empresas creando todo tipo de ideas y modelos de negocios ligados a nuestras localizaciones geográficas en interiores, y aunque para muchos esto será mucha preocupación en términos de privacidad, para otros esto será otra mina de oro en el mundo de los negocios... Leer el resto de este artículo... autor: josé elías |
|
|
|
|
|
domingo, junio 8, 2014
|
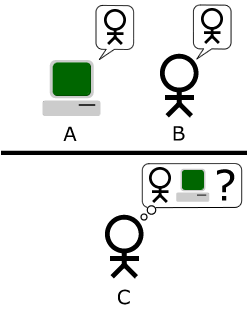 Una IA desarrollada por científicos rusos y de nombre "Eugene Goostman" acaba de engañar a unos cuantos jueces que pensaron que la IA era en realidad un joven de 13 años (fuente). Sin embargo, antes de que entiendan mal la noticia, hablemos de qué realmente fue lo que pasó acá, y así lo ponemos en contexto sobre su real significado (que no deja de ser sorprendente)… La prueba que esta IA superó se llama la Prueba de Turing (o el Turing Test en su versión original en inglés), y es algo de lo cual les he hablado por años en eliax, y se refiere a un examen desarrollado por el científico Alan Turing (uno de los héroes de mi vida) en 1950 en una obra de su autoría titulada "Computing Machinery and Intelligence". Para el que no lo sepa, Alan Turing es además el padre de La Máquina Universal de Turing, que es el marco teórico bajo la cual funcionan todas las computadoras digitales de hoy día. La idea detrás del examen es que si uno no puede discernir entre las respuestas que nos da una IA en relación a las respuestas que nos daría una persona, que entonces podemos decir que esa IA tiene al menos la inteligencia que asumiríamos tendría la persona a quienes creíamos estábamos cuestionando. La prueba se hace de la siguiente manera: Se colocan dos terminales de computadoras en habitaciones diferentes, en donde en una habitación se encuentra el jurado, y en otra se encuentra o una IA o una persona real, y ambos interactúan por medio de una pantalla y un teclado. La idea es que el jurado (que hará todas las preguntas) nunca pueda saber si lo que escribe en sus pantallas en la otra habitación es una IA o una persona tradicional. Cuando inicia la prueba, el jurado puede hacer cualquier pregunta que le plazca, sin restricciones. Así que por ejemplo le puedes hacer preguntas como “¿Viste alguna de las películas de Harry Potter, y qué te parecieron?”, o “¿Vas o fuiste a algún colegio?”, “¿cuál es el nombre de tu profesor de matemáticas?”, “¿cuáles son tus actividades favoritas?”, “¿cuándo fue la última vez que te enfermaste y qué hiciste tu o tus padres?”, "¿Cómo te sientes hoy?", etc. En este caso en particular, al jurado se le dijo que estarían entrevistando a un joven de 13 años de nombre Eugene Goostman, y asombrosamente, el programa de IA pudo engañar al 33% de los jueces (es decir, a 1 de cada 3), lo que convierte a esta IA en la primera en pasar la prueba en toda la historia (para pasarla, se requiere que al menos un 30% de los jueces sean engañados). Así que para empezar, no nos emocionemos bastante pensando que esta IA puede engañar a cualquiera, aunque sí hay que admitir que engañar a 1 de cada 3 personas ya de por sí es un gran hito. La otra cosa es que el hecho que esa IA pueda engañar a estas personas, no significa que esté consciente de su existencia (lo más probable en este caso es que no lo esté), debido a que es bastante posible que para pasar el examen estemos frente a un super-sofisticado sistema que entiende el lenguaje humano, y que accede a una gran base de datos con posibles respuestas, y se asiste de un componente de reconocedores de patrones (no muy diferente a como quizás funciona los reconocedores de patrones en nuestros cerebros). Pero aun así, el resultado es momental, y todo este tema de Inteligencias Artificiales recuerda el tiempo cuando la mayoría de personas (incluyendo expertos en varias diversas ciencias) decían que era imposible que una “mente digital” le ganara a un maestro de ajedrez, hasta que Gary Kasparov perdió de la supercomputadora Deep Blue de IBM en 1997... Después que esa supercomputadora ganó, los previamente escépticos cambiaron su mensaje desde “es imposible” a “esa supercomputadora en realidad no es inteligente, simplemente tenía tanto poder crudo de computación que analizaba de forma bruta las millones de posibles jugadas de ajedrez posibles para así poder ganarle a Kasparov”, pero la realidad que estos escépticos parece no poder ver es el hecho innegable (por la neurociencia) que al final del día nuestros cerebros (y por extensión, todo nuestro ser) no es más que una máquina extremadamente compleja que ejecuta toda forma de cálculos complejos, y particularmente, reconocimiento de patrones. La única diferencia entre una IA y nuestros cerebros, es que nuestros cerebros hacen computación en un ambiente biológico (específicamente, en un ambiente neuro-químico), mientras que una IA tradicional utiliza computación binaria digital (y en un futuro no lejano, computación cuántica, computación óptica, computación molecular, etc). Pero por pura deducción matemática, es importante notar que cualquier tipo de computación es equivalente a cualquier otra, independientemente de medio en que esta se ejecute. Sin embargo, a diferencia de nuestros cerebros, que evolucionan a un ritmo extremadamente lento (en relación a nuestras máquinas), las IAs evolucionan exponencialmente, lo que significa que no tardará mucho en que desarrollaremos una IA que iguale el intelecto de la persona promedio, y muy poco tiempo después de esa veremos una próxima generación con un intelecto al nivel de cerebros como los de Einstein o Newton, y debido a que ese crecimiento es incesante (siempre y cuando no nos encontremos con los límites de la física), al poco tiempo veremos IAs con mentes que nos superarán en básicamente todos los sentidos imaginables, desde potencia de cálculo en crudo, hasta inteligencia emocional, artística, o creativa, y cuando ese tiempo llegue, ya sabremos que estaremos en la cúspide de La Singularidad. Bienvenidos al futuro… Actualización: Varios lectores han reportado como este logro supuestamente no es lo que parece (todos apuntando al mismo enlace de un escéptico en Internet), sin embargo, escribí un contra-argumento a eso, que pueden leer en mi comentario #24.1 en los comentarios de este artículo. autor: josé elías |
|
|
|
|
|
lunes, junio 2, 2014
|
|
Impresiones generales Este evento de hoy se caracterizó por estas cosas: 1. A diferencia de eventos anteriores en donde Apple mezclaba las presentaciones para desarrolladores de software con anuncios de hardware (sean nuevas Macs, iPods, etc), hoy Apple aparenta que decidió que el evento WWDC será exclusivamente para temas de desarrolladores de software (que lo veo muy bien), tocando temas para consumidores solo en esos casos en donde deben hacerlo (es decir, aplicaciones y herramientas que llegan hasta el usuario final). 2. Apple siempre ha sido relativamente diplomática en relación a mencionar a Android en escenario, pero esta vez no tuvo la menor timidez en mencionar todas las debilidades de Android, y en resaltar las de Apple. 3. Apple sin duda que ha tomado pistas de la competencia para mejorar sus ofertas, particularmente de Google y hasta de WhatsApp (detalles más adelante). 4. Aunque rara vez se cuestiona si Apple escucha a los consejos y quejas de desarrolladores o no, esta vez Apple envió un contundente mensaje: Los escuchamos. Y prueba de ello fueron los anuncios del día que van desde extensiones nativas al sistema operativo, hasta un nuevo lenguaje de programación. 5. Estoy bastante seguro que los que esperaban nuevos anuncios de Macs, iPhones, iWatch y nuevos Apple TV, quedaron decepcionados, pero al otro lado de la moneda, este ha sido el keynote de Apple para desarrolladores de software que más me ha gustado de todos en su historia... 6. Finalmente, vimos más que nunca una profunda integración entre iOS y OS X, por lo que creo que este es un excelente momento para leer mis predicciones pasadas sobre lo que bauticé en ese entonces como "iOS X" hace 4 años... Leer el resto de este artículo... autor: josé elías |
|
|
|
|
|
domingo, mayo 18, 2014
|
 Pero parece que mi análisis y predicción del suceso dieron directamente en el clavo, pues Facebook acaba de anunciar precisamente lo que predije ellos harían con esta tecnología: Una nueva generación de mundos virtuales, una especie de Facebook en un mundo tangiblemente virtual. Por ahora no tenemos muchos detalles sobre la forma que tomará este mundo al estilo MMO (un mundo masivo en escala para múltiples personas en tiempo real, por sus siglas en inglés), pero si nos llevamos de las palabras que emitió justo anoche el CEO de Oculus, Brendan Iribe, el objetivo es ingresar a al menos "mil millones de personas" a este nuevo mundo virtual. ¿Tendrá éxito Facebook con esto? Pues ciertamente Facebook es una de las empresas mejor posesionadas para hacer esto realidad, junto a empresas como Google, Apple, Amazon, y empresas de video-juegos como Sony, Microsoft y Nintendo. Y hablando de esos otros jugadores del mercado, es bueno notar (como también publiqué y opiné en Marzo acá en eliax) que Sony ya se está armando para entrar con ambos pies a la batalla de los mundos virtuales inmersivos. No solo ya ha anunciado y demostrado a la prensa su "Project Morpheus", sino además reveló que el motivo de existir la extraña luz detrás de los nuevos controles del PlayStation 4, fue para soportar su tecnología de VR (Realidad Virtual) de Morfeo cuando esta estuviera lista para el mercado, lo que nos indica que la empresa ha estado planeando bien su jugada en el espacio. Eso de paso hará que las millones de personas que han estado utilizando por años el mundo virtual de Second Life, tomen nota del esfuerzo de Facebook y posiblemente se conviertan en sus primeros grandes adoptantes. Facebook (y Sony) mientras tanto, tendrán que superar un par de obstáculos antes de que esta tecnología se masifique... El primero de esos obstáculos es el precio de estos dispositivos. En teoría Facebook debería poder bajar el precio del Oculus Rift por debajo de los US$300 dólares, y si la empresa o Sony llegaran por debajo de los US$200, eso quizás sería suficiente para crear una masa crítica de "adoptantes primerizos" lo suficientemente grande como para que la tecnología se masifique viralmente a cientos de millones de usuarios, o quizás a los miles de millones que aspira Facebook (y es mi opinión personal que tarde o temprano eso sucederá, sea con o sin Facebook. No es cuestión de si sucederá o no, sino más bien de cuando)... El otro obstáculo es el tema de comodidad de las gafas (pues podrían pesar lo suficiente como para ser incómodas por largos períodos de tiempo) y el tema del lag (retraso entre uno expresar la acción a sus músculos de querer mover la cabeza y el cuerpo, y el tiempo que toma en uno percibir el movimiento dentro del mundo virtual). Sin embargo, en ambos casos aparenta que estas empresas están avanzando muchísimo, y además es importante notar que una de las grandes ventajas del Oculus Rift (y posiblemente de PS Morpheus) es que son una de esas tecnologías que cuando uno las prueba por primera vez uno queda anonadado. Similar al efecto que tuvo el novedoso control WiiMote del original Nintendo Wii, por lo que cuando menos el factor "¡uao!" está a favor de ellos, y no duden que más allá de Facebook y Sony que tarde o temprano veremos a los demás jugadores entrar también al mercado... Y a propósito, parece que esta otra predicción mía de hace un par de años también se está haciendo realidad... autor: josé elías |
|
|
|
|
|
jueves, mayo 15, 2014
|
 Hoy los dejo con este interesantísimo video de lo que ocurre cuando combinas las gafas de Realidad Virtual Oculus Rift (ahora propiedad de Facebook), y los sensores tridimensionales Kinect del Xbox/Windows. Hoy los dejo con este interesantísimo video de lo que ocurre cuando combinas las gafas de Realidad Virtual Oculus Rift (ahora propiedad de Facebook), y los sensores tridimensionales Kinect del Xbox/Windows.Para los que no saben lo que ocurre, la persona (Oliver Kreylos) que tiene el visor puesto puede ahora verse a él mismo en el video tal cual es en la realidad (o al menos, de forma aproximada) ya que 3 sensores Kinect conectados en varios puntos de su habitación capturan su imagen en tiempo real y proveen una imagen virtual de su cuerpo (y silla) al mundo virtual desplegado antes sus ojos con las gafas virtuales. Noten que la mesa que ven justo frente a él, no existe, y es totalmente virtual, pero la experiencia se siente tan realista que él dice que sus piernas tratan de evitar las patas de la mesa virtual para evitar chocar contra ellas, aun en el mundo "real" no exista tal mesa. Algo a notar es algo que menciona el mismo investigador, y es el hecho de que aunque la imagen que se forma de su propio cuerpo en el mundo virtual no es perfecta, el hecho de que sus movimientos y apariencia sea tan parecida a su cuerpo real hace que él se sienta que literalmente está viendo su cuerpo, lo que aumenta considerablemente la experiencia de "estoy aquí adentro". Noten además que de vez en cuando él utiliza un punto de vista diferente al de él mismo para mostrar su cuerpo desde el punto de vista de un tercero, lo que debe ser una sensación extraña ya que es como salirte de tu cuerpo y verte a ti mismo. Y no duden por un segundo que en un futuro este tipo de cosas será órdenes de magnitud más realista que lo que vemos acá, incluso pudiéndose reemplazar el visor virtual que vemos dentro del mundo virtual, por la cara real de la persona, para así completar aun más la ilusión de que estamos en un Holodeck de Star Trek (particularmente cuando combinemos esto con más de una persona a la vez). ¡Gracias a todos los lectores que me alertaron de este video! fuente oficial con más detalles Video a continuación (enlace YouTube)... autor: josé elías |
|
|
|
|
|
miércoles, mayo 14, 2014
|
 Pero, ¿qué tal si uno quiere hacer zoom-afuera (hacer el mapa más pequeño) con una sola mano y sin soltar el celular, todo con el dedo pulgar? Pues aunque la mayoría desconoce este truco, en mi opinión es uno de los más poderosos y útiles que tiene Google Maps, y es bastante sencillo. Para lograrlo solo basta hacer doble-toque en la pantalla, y dejar el dedo pegado en la pantalla con el segundo toque (es decir, no volverlo a retirar de la pantalla). Eso pone a Google Maps en un modo especial para hacer zoom (aun no tengas una pista visual al respecto en la pantalla), y ahora lo único que tienes que hacer (aun con el dedo pegado a la pantalla después del segundo toque), es deslizar el dedo hacia arriba o hacia abajo. Notarás que mientras deslizas el dedo hacia arriba o hacia abajo que eso causa que el mapa rápidamente cambie de tamaño. Así que en resumen: Doble-toque, dejar el dedo pegado después del segundo toque, y después deslizar el dedo hacia arriba o hacia abajo. Y si alguien conoce otros tips que desea compartir con los demás, utilicen los comentarios acá abajo en eliax… autor: josé elías |
|
|
|
|
|
jueves, mayo 8, 2014
|
 Esta noticia de hoy de seguro que la verán en varios portales de ciencia y curiosidades (como acá en eliax), pero en muy bajas dosis en portales populares de noticias (tanto en red como en TV y radio), lo que es una tremenda pena ya que esta es una noticia de increíble importancia a nivel general... Esta noticia de hoy de seguro que la verán en varios portales de ciencia y curiosidades (como acá en eliax), pero en muy bajas dosis en portales populares de noticias (tanto en red como en TV y radio), lo que es una tremenda pena ya que esta es una noticia de increíble importancia a nivel general...Se trata de que por primera vez se ha logrado que ADN modificado con moléculas sintéticas se replique en organismos vivientes. ¿Qué significa eso en un lenguaje más claro? Pues aquí vamos... Como casi todos saben, el ADN es nuestro "plano maestro". No es más que una larga molécula que contiene todas las instrucciones para crear una forma de vida, sea animal, vegetal, o mezcla de ambas, y por tanto es también el mecanismo que describe cómo crear un ser humano. Todo ser vivo que dependa de ADN, tiene una copia de este "plano maestro" en todas y cada una de las células de su cuerpo, y por eso es que cuando un esperma fecunda un óvulo, lo que en realidad está haciendo es pasando el ADN del padre para que se mezcle con el ADN de la madre, y de la unión de ambos obtenemos un nuevo plano para una nueva persona, y ese nuevo plano se copia trillones de veces acorde crece el bebé, y se convierte en parte de todas las células que lo componen. Pues bien, este "plan maestro" o "código maestro" es, en cierta forma, un lenguaje de programación, el cual utiliza apenas 4 "unidades básicas" que al combinarse en miles de millones de formas, se convierten en nuestro ADN. Esas 4 unidades básicas (o "bases nitrogenadas" en lenguaje técnico) las conocemos como Adenina (A), Citosina (C), Guanina (G) y Timina (T). Y noten que en una molécula relacionada al ADN, llamada ARN, tenemos una quinta unidad llamada Uracilo (U), pero eso no nos concierne para este artículo de hoy. Estas "letras básicas" del alfabeto de la vida usualmente vienen en pares, de modo que las vemos como A-T y C-G en nuestro material genético, y lo que los científicos han logrado ahora es insertar dos nuevas letras a este alfabeto (que en este artículo en eliax llamaremos E y X, pero que técnicamente son llamadas "d5SICS" y "dNaM"). Entonces, ¿qué es lo asombroso de esto? Pues dos cosas: Lo primero es que se pudieron incorporar esas otras dos letras, E y X, en el ADN sin problemas secundarios, y lo segundo es que este nuevo código se traspasó genéticamente a futuras generaciones. O en otras palabras, los padres transmitieron este nuevo código, ahora de 6 "letras", a sus hijos, y ellos a futuras generaciones. O en otras palabras, el organismo asimiló a estas nuevas letras E y X como algo natural de su existencia. En este caso en particular, el organismo con el cual se experimentó fue en una variante de laboratorio de la bacteria del E.Coli, la cual aun de un tamaño microscópico, comparte mucho de su ADN con nosotros (pues todos los seres vivos que compartimos ADN provenimos de un ancestro común, por lo que compartimos buena parte de nuestro ADN). Pero, más allá del factor "okey, chévere", ¿qué significa esto? Pues significa que ahora hemos verificado que la vida no depende de esas 4 letras básicas, sino que muy posiblemente puede utilizar una cantidad arbitraria de letras, lo que significa una posible complejidad asombrosa de formas de vida que podrían evolucionar de esto. Esto por un lado agrega más leña al fuego de que la vida debe ser algo bastante común en el resto del universo, y por otro lado nos ofrece evidencia de que podremos modificar nuestro componente genético en formas aun inimaginables. Esto por ejemplo podría tener profundas implicaciones en no solo temas de salud (con toda una nueva generación de terapias personalizadas a cada individuo, algunas de las cuales podrían extender nuestras expectativas de años de vida dramáticamente), sino además en procesos industriales en donde podríamos diseñar nuevas formas de vida que nos ayudarían a hacer cosas que van desde limpiar materiales radioactivos hasta minar la energía del medio ambiente en todas sus posibles formas. O en otras palabras, estamos ante el umbral de lo que podría ser una de las más grandes revoluciones en bio-informática en toda la historia de la humanidad... ¡Gracias a todos los lectores que me alertaron a esta noticia por distintos medios! fuente 1 fuente 2 autor: josé elías |
|
|
|
|
|
viernes, abril 25, 2014
|
 Uno de los atributos más humanos que muchos pensaban nunca sería conquistado por las máquinas, acaba no solo de ser conquistado, sino de hacernos obsoletos... Uno de los atributos más humanos que muchos pensaban nunca sería conquistado por las máquinas, acaba no solo de ser conquistado, sino de hacernos obsoletos...A la fecha, ningún algoritmo de software de Inteligencia Artificial había podido romper la barrera de reconocimiento facial de los humanos (es decir, nuestra habilidad de poder distinguir entre caras, o de poder asociar distintas imágenes de caras a la misma persona). Hasta ahora, el software que más se había acercado a romper esta barrera era el de Facebook, del cual les hablé hace exactamente un mes acá en eliax, el cual puede reconocer caras humanas con una eficiencia de un 97.25%. Los humanos mientras tanto, tenemos en promedio un 97.53% de aciertos, pero un nuevo software acaba de romper ese límite, pudiendo reconocer caras con un 98.52% de aciertos. Eso significa que ahora las máquinas son mejores que nosotros mismos, en reconocernos a nosotros mismos. El algoritmo que ha logrado esta hazaña lo han bautizado como GaussianFace, y lo que hace es transformar cada cara que ve (independientemente de su resolución original como es captada por una cámara digital) a una imagen de apenas 150 x 120 pixeles, en donde se evalúan solo 5 áreas específicas de las caras de las personas, las cuales son la posición de cada uno de los ojos, la posición de la nariz, y la posición y forma de las dos esquinas laterales de la boca. Así que ya me puedo imaginar un futuro no lejano en donde cuando combinamos esta tecnología con esta otra que puede extraer de nuestras mentes las caras que imaginamos, obtendremos asistentes digitales (similares a este) que aparentarán verdaderas extensiones de nuestros cerebros para ayudarnos a interactuar con otros seres humanos en formas que hoy día apenas podemos empezar a imaginarnos... documento científico original fuente secundaria autor: josé elías |
|
|
|
|
"Ojalá me equivoque, pero creo que jamás veré la película igual. Lo que decías Elías, ver al público disfrutar y celebrar la película, nunca lo había visto antes de esta forma, casi parecía la final de un partido de fútbol. 20 sobre 10"
página 3 de 54
en total 864 entradas en Software
 página anterior
1
2
3
4
5
6
7
8
...
página siguiente
página anterior
1
2
3
4
5
6
7
8
...
página siguiente
en total 864 entradas en Software
en camino a la singularidad...
©2005-2026 josé c. elías
todos los derechos reservados
como compartir los artículos de eliax
Seguir a @eliax